WebGL Forward+ and Clustered Deferred Shading
The browser renderer implemented with Forward+ Shading and Clustered Deferred Shading techniques can render a scene with hundreds of lights efficiently. Access the LIVE ONLINE DEMO here!

Features
- Forward+ rendering
- Clustered deferred rendering
- Deferred Blinn-Phong shading
- Optimized g-buffer format:
- Pack values together into vec4s
- Use 2-component normals
Performance Analysis
The following analysis tested on a display with 60 Hz refreshing rate.
-
Performance Comparison among Forward, Forward+, and Clustered Deferred Rendering
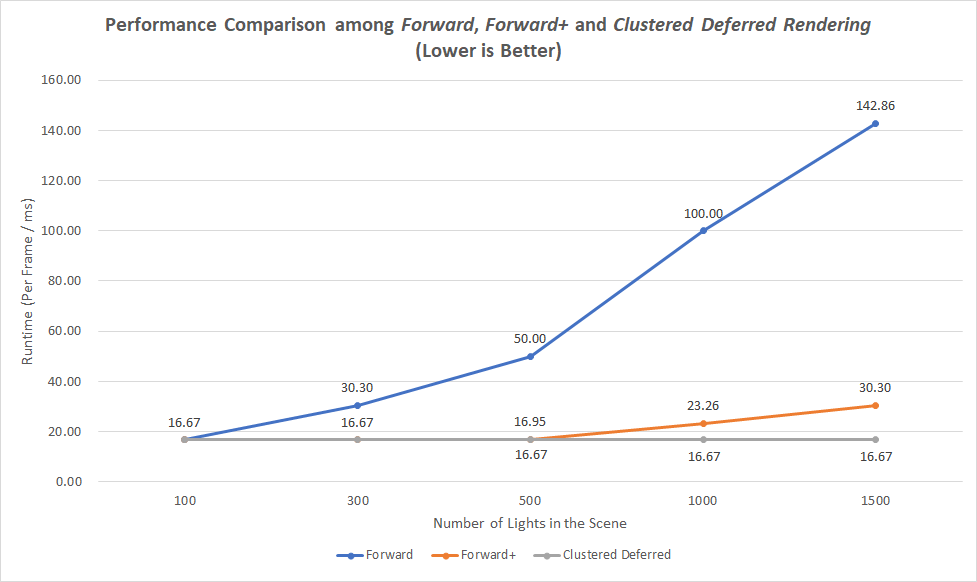
This comparison was done with the condition
MAX_LIGHTS_PER_CLUSTER = 300. As the number of lights increases, the forward rendering performs worse and worse, there exists a huge performance gap between the forward rendering and the other two advanced methods. As we can see, when the number of lights is larger than 500, the forward+ rendering gradually spends more runtime than the clustered deferred rendering, while the clustered deferred rendering always has the best performance among the three methods. -
Performance Comparison between Forward+ and Clustered Deferred Rendering in Different Numbers of Slices
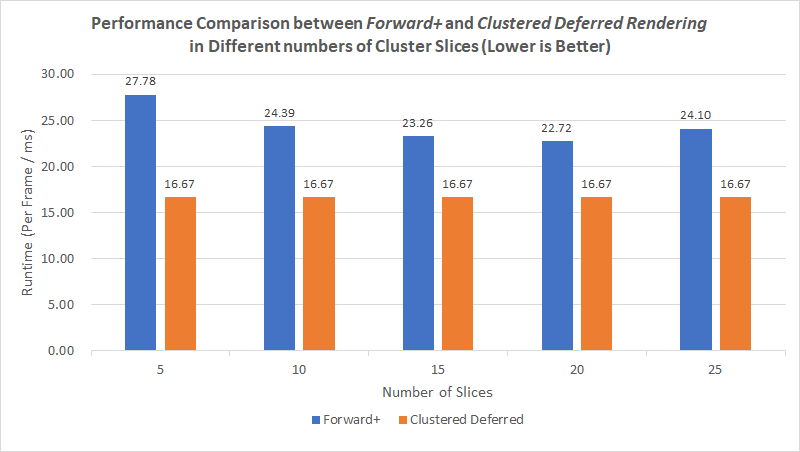
First, this comparison also shows that the clustered deferred rendering outperforms the forward+ rendering, even under different number of slices.
Second, from the above inset we can get that, the number of slices between 15 to 20 achieve the best performance. If the number of slices is too small, each cluster will have a larger size which means that it will take more time to do the triple loop of searching intersecting lights, so no best performance can be achieved under this situation. However, if the number of slices is too larger, each cluster only contains a little bit number of lights, the program will takes more time to locate the buffer with lights. Besides, because my display only has 60 Hz refreshing rate, and this comparison was done with the condition
NUM_LIGHTS = 500 && MAX_LIGHTS_PER_CLUSTER = 300, therefore, the clustered deferred rendering can always use all the hardware resources reasonably, so its runtime doesn’t change. -
Performance Comparison between Unoptimized and Optimized Clustered Deferred Rendering
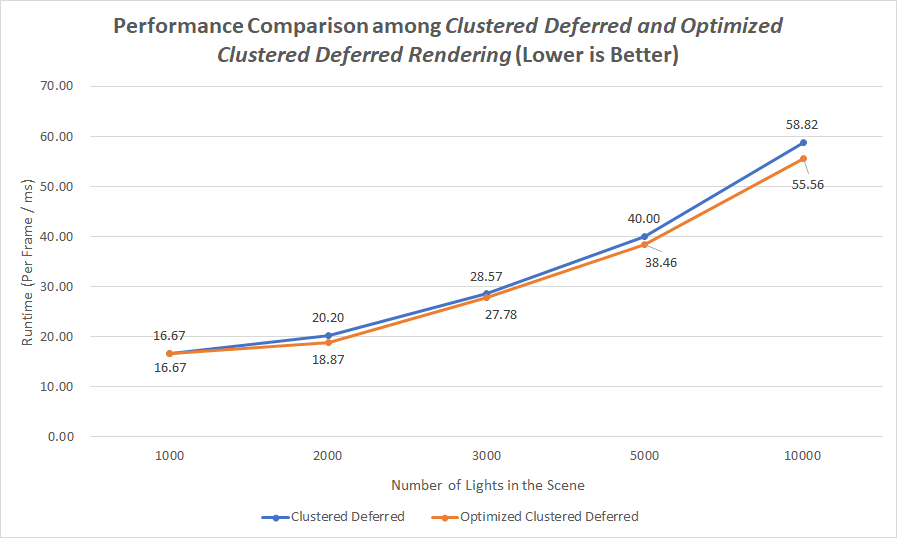
I compressed the 3D normals into 2D (only passing normal.x and normal.y into G-Buffer), and packed values together into vec4s, so that after optimization, only 2 G-Buffers were used in the final result.
// color.xyz & position.z gl_FragData[0] = vec4(col.x, col.y, col.z, v_position.z); // normal.xy & position.xy vec2 compressedNorm = compressNormal(norm); gl_FragData[1] = vec4(compressedNorm.x, compressedNorm.y, v_position.x, v_position.y);The above performance comparison was done with the condition
MAX_LIGHTS_PER_CLUSTER = 1000. Obviously, because less G-Buffers were used to read and write data, the optimized method achieves a better result.
References
- Three.js by @mrdoob and contributors
- stats.js by @mrdoob and contributors
- webgl-debug by Khronos Group Inc.
- glMatrix by @toji and contributors
- minimal-gltf-loader by @shrekshao